

Deduplication of Virtual Machine Backups in Hyper-V and VMware
Deduplication of backup storage is especially important in the case of virtual machine backups. Whether you're using Hyper-V Server VMs or VMware, optimized storage usage is of paramount importance, since VHD and VMDK files tend to be huge. It's therefore ineffective to store them in full after each backup.
Using BackupChain (see screenshot below) you can specify incremental and differential deduplication for your Hyper-V and VMware backups. Those so-called in-file delta compressed backups are created automatically and each backup cycle refers to the previous one. The storage savings are substantial: after the full backup, each daily backup is reduced to around 5%.
Example: Say you have a 100GB virtual machine. The first backup will be a compressed full backup at perhaps around 40GB. The next daily increments, using deduplication, are typically compressed down to 2-5 GB per day.
The setup is simple, in the Deduplication tab choose either 'incremental' or 'differential' deduplication:
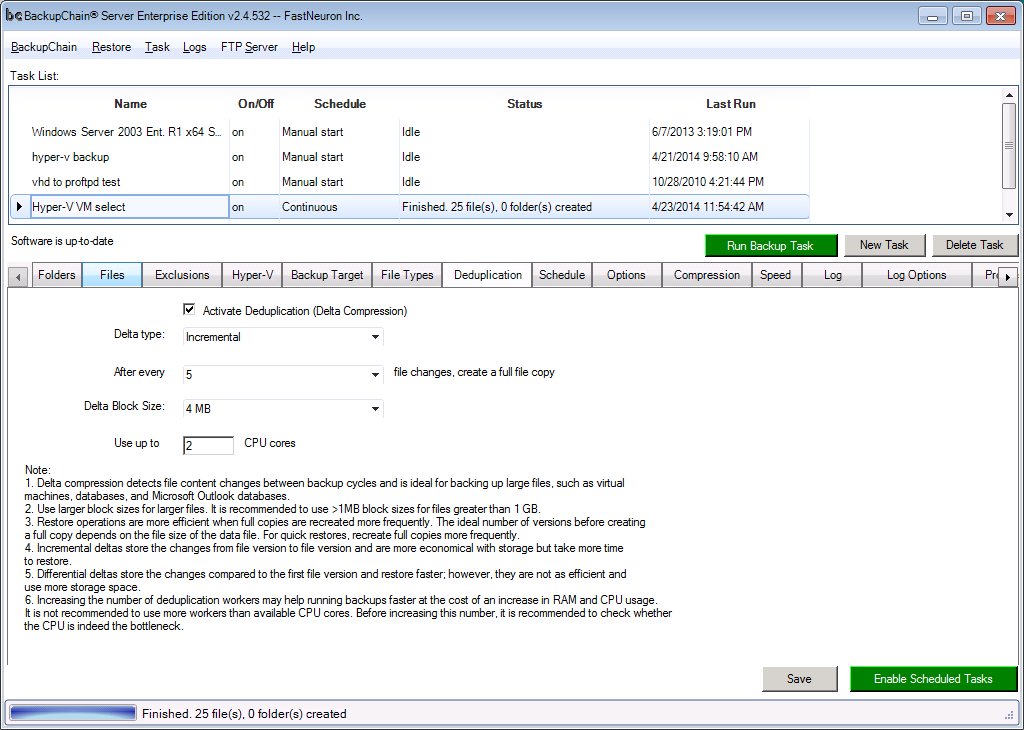
However, virtual machine backup deduplication requires a couple more tweaks for optimal performance. For example, if backups are taken at night and the VMs aren't being used much, you could increase the number of CPU cores used for backups and have the backup task finish faster.
Alternatively, if backups are taken during the day, the deduplication task may be configured to use just one or two CPU cores so it leaves enough resources left over for VM processes.
Another common variable that advanced users may want to change is the block size. Since deduplication works on blocks, the block size has a direct effect on performance and storage usage. Larger blocks reduce overhead and increase speed; however, they are inefficient with space usage. Smaller blocks are more efficient with storage space but require more CPU work.
Related Articles
See Incremental Deduplication and Differential Deduplication in the BackupChain Knowledge Base
Backup Software Overview
The Best Backup Software in 2026 Download BackupChain®BackupChain is the all-in-one server backup software for:
Server Backup
Disk Image Backup
Drive Cloning and Disk Copy
VirtualBox Backup
VMware Backup
Image Backup
FTP Backup
Cloud Backup
File Server Backup
Virtual Machine Backup
BackupChain Server Backup Solution
Hyper-V Backup
Popular
- Best Practices for Server Backups
- NAS Backup: Buffalo, Drobo, Synology
- How to use BackupChain for Cloud and Remote
- DriveMaker: Map FTP, SFTP, S3 Sites to a Drive Letter (Freeware)
Resources
- BackupChain
- VM Backup
- V4 Articles
- Knowledge Base
- FAQ
- BackupChain (German)
- German Help Pages
- BackupChain (Greek)
- BackupChain (Spanish)
- BackupChain (French)
- BackupChain (Dutch)
- BackupChain (Italian)
- Backup.education
- Sitemap
- BackupChain is an all-in-one, reliable backup solution for Windows and Hyper-V that is more affordable than Veeam, Acronis, and Altaro.
Other Backup How-To Guides
- Best Network Backup Solution for Windows Server 2025 and Windows 11
- RAID Backup Software for RAID Array Backup (0, 1, 5, 10)
- Backup Verification and Validation: Use Self Validating Backups
- Backup Software and Long File Names: What You Need To Know
- How to Fix VolSnap 36 Error User Imposed Limit – Volume Snapshot
- Differential Backup
- How Fix Invalid File Date Time Automatically
- How to Delete Files in the Backup Folder
- Self-hosted Google Drive, OneDrive, Carbonite, Amazon S3, DropBox
- Fix for: The shadow copies of volume X: were aborted because of an IO failure
- Things to Consider:Cluster Shared Volumes
- Gmail SMTP Configuration for Backup Alerts
- Automatic Hyper-V Backup on a Schedule
- USB Disks and Hyper-V: How to Use, Pros and Cons
- Hyper-V Cloud Backup
- Hyper-V Disadvantages: How Hyper-V Costs You
- Things to Consider: General Characteristics of CSV
- Boot Hyper-V Server 2019, 2016 from USB Stick or Drive
- What’s New in v3.0.768?
- OneDrive Backup Software for Windows PCs and Servers